SpeakIn

2021-3-6
国音智能获VoxSRC2020声纹识别比赛Track1、Track2双榜第一
3月5日消息,国音智能在VoxSRC2020全球声纹识别挑战赛中(永久开放阶段)刷新记录,Track1、Track2任务性能指标均排第一,有力证明了国音智能声纹识别技术已达世界最佳水平。
固定训练集Track1 DCF0.1670%,EER 3. 1870%,排名第一。
开放训练集Track2 DCF 0.1670%,EER 3. 1870%,排名第一。
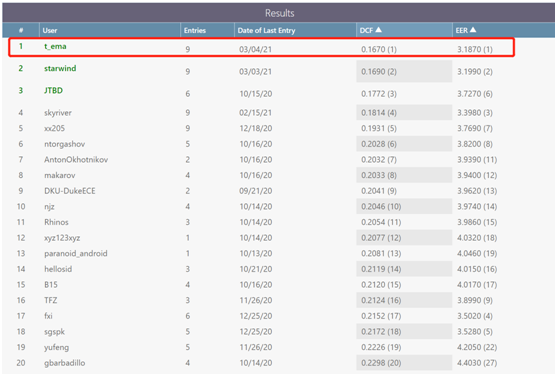
(固定训练集Track1)
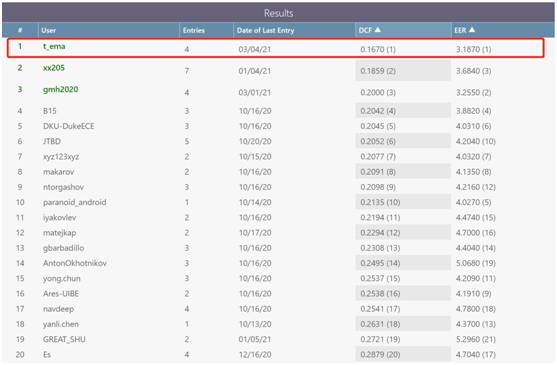
(开放训练集Track2)
The VoxCeleb Speaker Recognition Challenge 2020(VoxSRC2020)比赛是牛津大学、麻省理工学院林肯实验室、斯坦福语音技术研究实验室、韩国Naver等联合发起的全球性声纹识别比赛。该榜单的挑战者高手云集,包括比利时根特大学(Ghent Uni.)、美国约翰霍普金斯大学(JHU)、微软研究院、捷克布尔诺理工(BUT)等,以及清华大学、昆山杜克、思必驰、科大讯飞、平安科技、依图科技等,国内外一流高校、研究机构和企业。目前该榜单处于永久开放阶段。
Track1和Track2均为文本无关声纹识别任务。其中,Track1采用指定VoxCeleb2 dev数据集作为训练集,Track2则可使用测试集之外任何开放数据作为训练集。要强调的是,国音在Track2提交结果中采用模型与Track1一致,仅使用了指定的VoxCeleb2 dev数据集作为模型训练集,若采用开放数据集训练的模型,成绩将更佳。
半年精心专研,实现前端到后端全方位模型优化
VoxSRC2020声纹识别任务,实质上是较短时长条件下的声纹识别难题。对此,由许敏强博士带领的声纹研发团队耗时半年,从数据处理、特征提取、信息表达、信息补偿全流程剖析,全方位优化,最终获得高性能声纹模型,显著提升了复杂场景下说话人识别效果。
人才汇聚,拥有世界顶尖AI算法科研团队
国音智能云集了⼀批世界顶尖的AI算法科研⼈才,以及来⾃BATH等知名互联⽹企业的产品研发团队,具有极强的科研实⼒与产品研发能⼒。团队核⼼成员分别来⾃麻省理⼯、UIUC、JHU、美国东北⼤学、⾹港⼤学、中国科技⼤学、复旦⼤学、上海交通⼤学、微软亚洲研究院等国内外⾼等学府和科研机构。
以助力城市数字化建设为使命,让机器更好的服务于人
国音智能自2015年创建以来,以语音技术研发为起点,在拥有强优势的声纹识别技术同时,逐渐开展语音识别、语音合成、自然语言处理、信号处理等多种语音语义技术栈研究,在城市治理、公共安全、民生民计、智能制造等数字化城市建设中发挥重大作用,旨在以先进的人工智能技术和传感技术为驱动,加速城市数字场景的智能化进程。
未来,国音智能将不断拓展“端+云”能力,合作打造智能终端应用产品,赋能更多行业,帮助构建和强化更便捷更安全的数字化城市生活。